
Written by Alex Kim, Open Mainframe Project Mentor and Contributor to Zowe
This blog originally ran on the Zowe Medium site. For more content like this, click here.
For many years, mainframe system programmers, as well as middleware managers, have been relying on z/OS systems data called SMF (System Management Facility) records and RMF (Resource Measurement Facility) records to assist in understanding what is going on inside their mainframe environment. SMF/RMF records show how the mainframe is performing and the health of the system. Whether you are an experienced z/OS system programmer or a newbie interested in using performance data — you may find ZEBRA, currently an incubator under the Open Mainframe Project’s Zowe™, to be an interesting project.
Almost every part of the IBM mainframe — even in very low-level hardware logic — generates system statistical data during every machine cycle, so whenever an operation exception occurs, engineers can look at the data to understand what happened and why. The secret of IBM mainframe reliability is based on design principle where engineers can put together proper metrics carefully to keep track of system (both hardware and software) behavior in multiple records. This mode of operation has been practiced for over a half century based on the best large-systems architecture, which never ceases to amaze.
Where SMF/RMF have been used so far…
RMF provides a key set of metrics used to understand core z/OS hardware resource utilization as well as its performance such as CPU, I/O (Storage and Networking etc.) and memory. When a mainframe client purchases a new generation of mainframe system, such as IBM z16, RMF can provide critical information about how many CPUs and other key HW features would be needed for their existing workload — most people call this ‘Capacity Planning’. RMF also provides key performance metrics to understand how z/OS workloads are doing so system programmers can determine if the system is providing enough computing capacity to meet its business goals.
SMF (which is mostly for software and z/OS as opposed to RMF hardware resource metrics) is also being used in many different ways for various IBM z/OS software components such as JES, Db2, WAS, CICS/IMS etc. You can almost tell how the software is performing if one has enough SMF data records and the tools to analyze them.
Why we started ZEBRA
In summer of 2020, I had the privilege to serve as a mentor for Open Mainframe Project Mentorship program and worked with a brilliant med-school student from Nigeria, Salisu Ali. I wanted to conduct a proof-of-concept design of how SMF/RMF data could be consumed along with many other open-source tools such as MongoDB and Grafana. At the time, there were no open-source tools that displayed RMF or SMF data into JSON format but many of modern data handling tools were commonly used with JSON data. Thanks to Salisu’s contributions, we were successful producing a simple NodeJS server translated RMF data from Distributed Data Server(DDS) for z/OS(a.k.a. GPMSERV) into JSON and fed into MongoDB, Prometheus and Grafana via a set of RESTful APIs.
In 2021, we decided to propose it to be an incubation project under Open Mainframe Project’s Zowe, calling it ZEBRA — Zowe Embedded Browser for RMF/SMF and APIs. The intent was to leverage the ZEBRA project to attract more contributors to join to develop and provide a means of RMF/SMF data thru REST APIs and to integrate with the Zowe’s API Mediation Layer. Of course, I wanted to have an animal representing the project(who doesn’t want an animal logo for FOSS project?) and couldn’t get any better idea than the zebra, which has wavy lines on its body — which can represent performance graphs in time series dashboard — and lives in the wild (feeling somewhat similar to being an incubation open source project directed by community and user needs).

How to start using ZEBRA
To start using ZEBRA in your environment, install NodeJS 10.x or higher on your PC or Server than clone it from github and do following:
git clone git@github.com:zowe/zebra.git
cd src
npm install
node bin/www
Once the NodeJS app has launched, you can open up a browser and check if the server is running well by visiting :
If you can see the screen like the one below, you are on the right track.
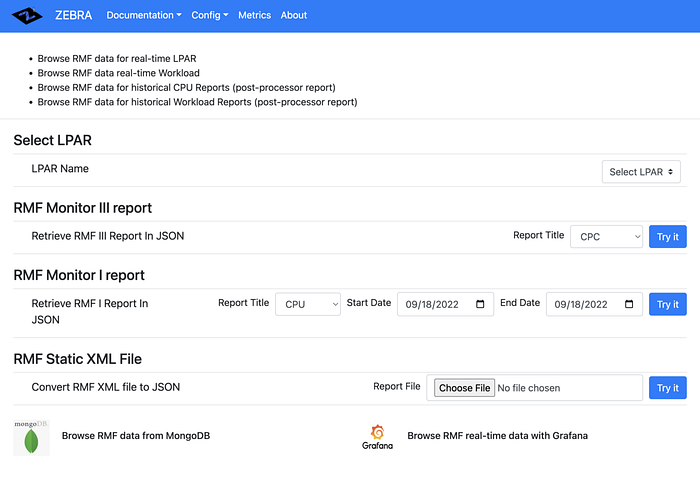
Of course, there is more configuration needed to connect to z/OS DDS server to get its RMF records types to be converted to JSON format thru ZEBRA.
To see what it would be like using ZEBRA for z/OS, you can simply visit its demo site to see it in action. No sign up or registration is required to access its APIs. If you want to see how it works with Grafana — you can request for the access thru its github issues.
One of the benefits of ZEBRA is that a user can have various ways to integrate & test how RMF data can be plugged into the open-source software in the market, without much hassle nor dependency from z/OS system programmers, as it is exploiting DDS server’s HTTP Web APIs.
One of the great use cases of ZEBRA is plotting RMF III real-time data into Grafana, which is one of the most popular open-source time series data plotting tool in the market today. Grafana is very versatile tool and provides many plug-ins to work with. Using Prometheus (another great open-source time series database). Grafana helps to display RMF data easily and effectively to anyone that has a web browser.
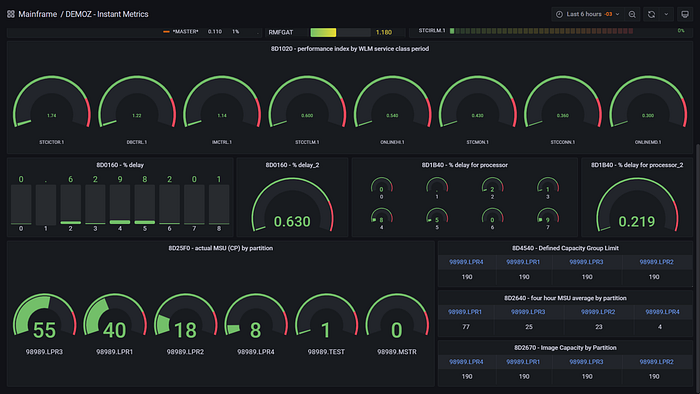
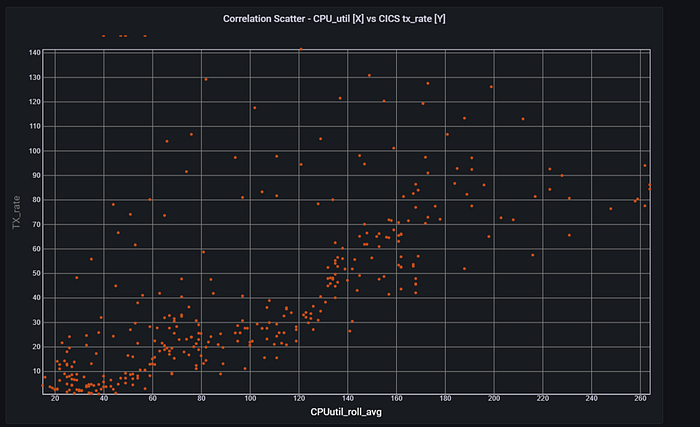
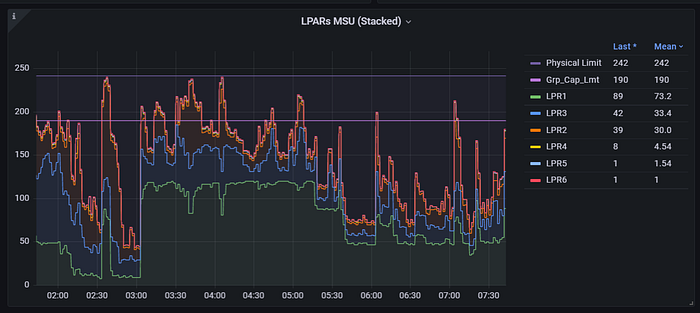
Some of the examples of how ZEBRA-to-Grafana use cases are posted in our ZEBRA Gallery, by our SME for ZEBRA, Fernando Zangari. Fernando’s use cases are real, as he is using ZEBRA to monitor many of the z/OS systems he manages today. If you are interested in watching his demo in action, you can watch replay from Linux Foundation’s Open Mainframe Summit . You can find the session information here( https://sched.co/157ek ) and the replay from here( https://youtu.be/-jkfL7PTQa8 ).
How you can join the ZEBRA project and participate
Since its launching as an incubation project, ZEBRA has been attracting many volunteer-based developers/contributors such as Salisu Ali, Justin Santer, Fernando Zangari, Carson Cook, Andrew Twydell, Agnaldo Da Silva and more. Recent work by Justin and Salisu has been focused on re-architecting ZEBRA with TypeScript to make it more scaleable/sustainable. Fernando’s contributions on how to use APIs to Grafana is huge. Carson’s work on engaging API ML tokens and Andrew’s demo of Zebra Desktop app show how it can work with Zowe. Agnaldo’s proposal on how ZEBRA can be covering other SMF records can be very important to many of system programmers out there. We hope to share more details on each of these activities with following up blogs.
We are hosting a bi-weekly team meeting every Thursday 8AM EST, and development team weekly scrum on every Friday 9:30AM EST. If you have questions and/or are interested in joining the these open-source activities, please join us on either meetings. We always welcome new members.
Want to learn more about ZEBRA? Check out this blog and video that takes a look at ZEBRA use cases in large production systems.
If you enjoyed this blog checkout more Zowe blogs here. Or, ask a question and join the conversation on the Open Mainframe Project Slack Channel #Zowe-zebra, #Zowe-dev, #Zowe-user or #Zowe-onboarding. If this is your first time using the OMP slack channel register here.